clash规则教程


了解生物信息学的科研人员或许都知道,通常情况下高通量测序产生的数据量动辄几百个G。个人电脑的配置难以支持如此大规模的数据分析任务,学生党们也难以承认配置达标的服务器的价格。科研猫在此郑重推出开源项目支持计划:32核256G内存高性能服务器,免费用!
生命科学大数据研究中,服务器是必不可少的硬件,没有服务器,想做生物信息是天方夜谭。在Dry Lab日常工作中,获取服务器的方法有很多,比如自己搭、租赁或者云计算。自己搭建服务器对硬件和机房、网络等设施要求较高,而且要有一定的维护技能,最关键费用很高,随便搞几个节点,没有几十万是下不来的。比如稍微简单点的,一台登录节点,两台双路的计算节点,一台存储节点,加上网卡、交换机,匹配上工业空调、UPS,每年合理的用电,这种方案毛估一下,50万起步。除非是专门做生物信息的课题组,一般常规课题组是不具备这个条件的。
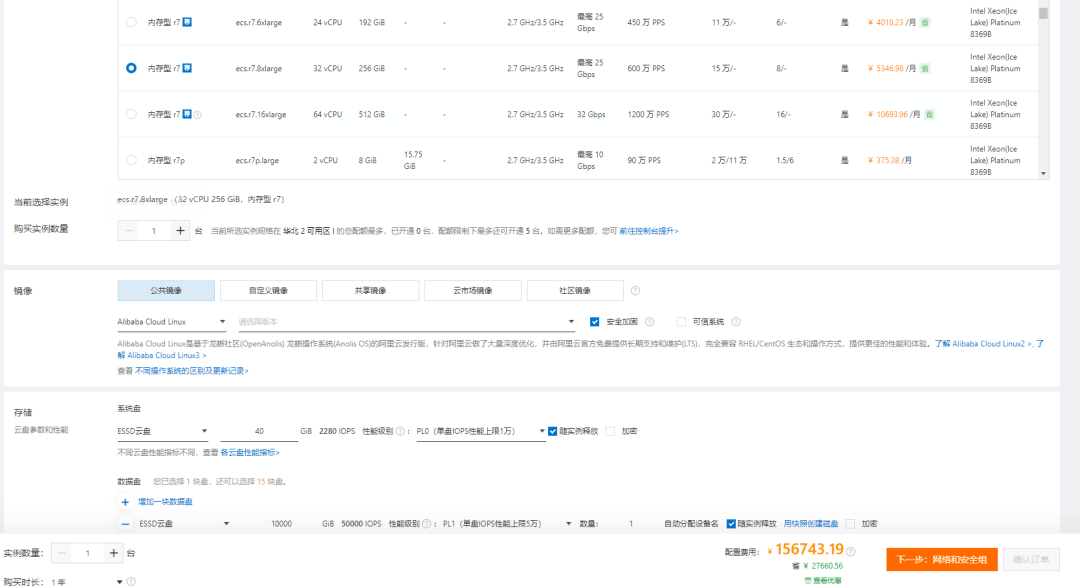
还有就是云计算,现在AWS、Azure、阿里云、腾讯云、华为云等云厂家为我们提供了大量的算力,而且极具伸缩性,根据计算任务的大小,可以选择适中的计算实例与其匹配,而且稳定,免维护,是短期计算任务的不二选择,但是其缺点就是长期使用的话,价格极其昂贵,特别是存储,10T的热存储一年都得十来万,算下来远不及自己买一两台服务器来的划算。我们在阿里云实测了一下,ecs.r7.8xlarge的实例,32vCPU 256G内存 10T存储,1年的费用是156743.19元,着实厉害!
总而言之,不管是自己搭建服务器还是用云计算厂商,服务器都是一笔不小的支出。把很多初学者或者非专业做计算的大量科研人员,卡死在大数据研究的第一步。
搞大数据计算,除了要求算力,还要有合适的计算工具。近几年来,中国科研人员发布的生物医学相关计算工具日渐增多,一些知名工具甚至在国际科研界也是享有名气,但是相较于国外知名机构,诸如Broad Institute这种生信研究的殿堂,我们还有太远太远的路要追赶。
为了促进国产化计算工具的发展,完善我们国家自己的生物信息生态圈,我们在去年11月发布了Hiplot Pro生物医学可视化及大数据分析平台()clash规则教程,网站自发布一来,20天突破1万用户,2个月突破百万人次访问,目前日访问量3.5万人次。在大家的热度不断增加的同时,我们也在不断思考,如何才能突破科研合作的桎梏,打造出以开源化理念为主导的计算平台,在真正意义上为中国科研界构建一个完善的生物信息生态圈。
我们一直说,我们甘做“为众人负薪者”,为了孵育和推动开源生物信息项目的成长,Hiplot在此郑重推出开源项目支持计划!
更加美好,更加宏大的未来在等待着我们去建设,“人人为我,我为人人”,早点加入我们的行列吧。返回搜狐,查看更多

